Bank of England Project: Can Language Predict Financial Risk?
📂 Data Sources:
Earnings Call Transcripts from JP Morgan & Citigroup (2015–2025)
Financial Statements (Income Statement, Balance Sheet, Cash Flow) via Alpha Vantage API
Macroeconomic Indicators (e.g. interest rates, GDP growth, unemployment, CPI)
EPS Estimates from analyst forecasts (manually sourced where needed)
🛠️ Tech Used:
Python (Pandas, NumPy, Scikit-learn, XGBoost, SHAP)
NLP Tools (FinBERT for sentiment, readability metrics: Flesch, Gunning Fog, SMOG, etc.)
Jupyter Notebooks (exploration, modelling, documentation)
Matplotlib & Seaborn (visualisation)
Alpha Vantage API (financial + macro data collection)
Spline Interpolation & Feature Engineering (to align and enrich quarterly data)
Colab Notebooks: NLP Notebook, Model Notebook
🧩 The Problem?
The Bank of England’s Prudential Regulation Authority (PRA) wants to spot early signs of instability in major banks using publicly available data. We were split into groups of six to devise how we would go about determining this. Our group decided that we should focus on one key red flag - negative earnings surprises (NES). When a company’s reported earnings fall short of what analysts expected, NES events can trigger market shocks and investor panic.
Executives often speak cautiously when things aren't going to plan. We explored whether the tone, clarity, and complexity of CEO/CFO language could act as a warning signal, even before the numbers come out.
The PRA was particularly interested in early-warning indicators beyond traditional balance sheet health. This project demonstrated how integrating soft signals (like executive tone) could support regulatory decision-making alongside quantitative risk models.
🌐 Why It Matters
Even a few quarters' early warning could help regulators prevent larger-scale financial risk. If linguistic signals can provide additional insight alongside traditional financial metrics, regulators may be able to intervene earlier. This has potential to contribute to overall financial stability – especially in Global Systemically Important Banks (G-SIBs) where early indicators of distress are vital.
This project also highlighted the importance of combining natural language processing (NLP) with financial modelling and showed how choosing the right evaluation metric and approach can shape what a model reveals.
🔢 What We Did
We built a model to detect when a large bank might miss earnings expectations using a combination of:
Financial indicators (e.g. Return on Equity, Cash Ratio, GDP growth)
Linguistic features (e.g. sentiment, vagueness, readability, jargon)
Earnings call transcripts from JP Morgan & Citigroup (2015–2025)
We framed the task as a binary classification problem, where NES was defined as EPS falling short of expectations by 5% or more. This threshold helped address the severe class imbalance, as negative surprises were rare.
Through exploratory data analysis, we found that no single feature had a strong linear correlation with NES - neither financial nor linguistic variables on their own were reliable predictors.
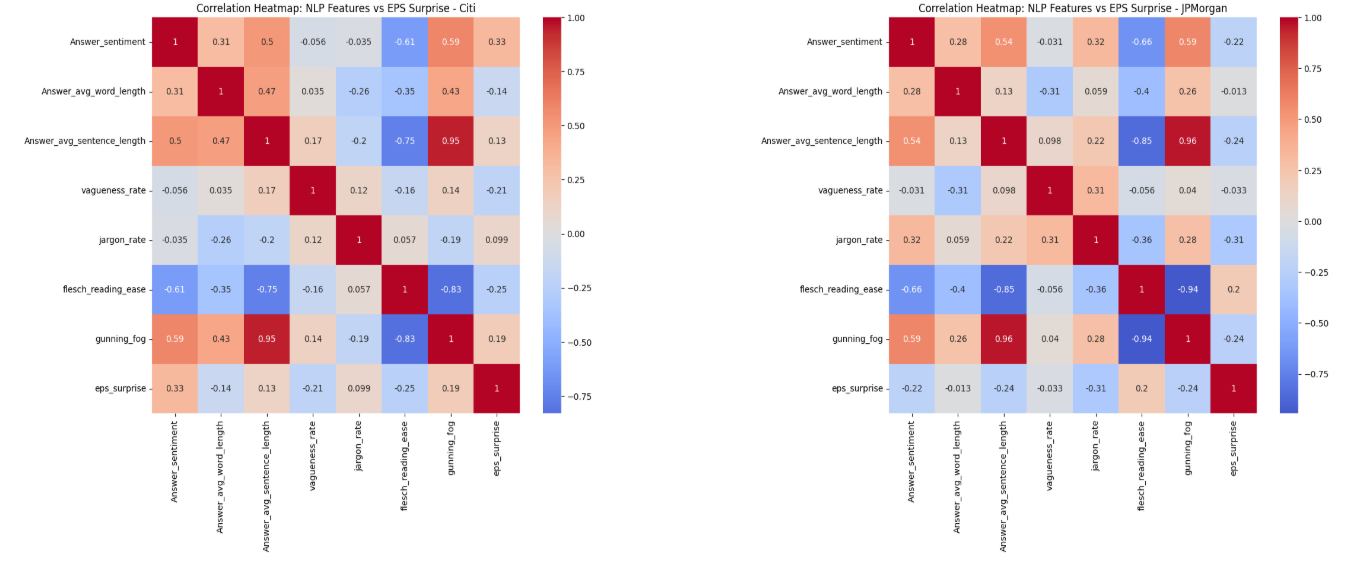
Correlation matrices of linguistic metrics vs EPS Surprise
This lack of clear linear patterns led us to select XGBoost, a gradient-boosted tree model capable of capturing complex, non-linear relationships between features. Its ability to perform well on small datasets, tolerate noisy features, and provide explainability via SHAP values made it well-suited to our problem space. Additional reasons for using XGBoost as our model were:
Model non-linear relationships
Perform well on small datasets
Handle noisy or irrelevant features without much preprocessing
I focused on:
Optimising the model for recall, since capturing NES (even with some false positives) was more important than avoiding false alarms
Addressing class imbalance through threshold adjustments and weighting
Leading documentation, visual storytelling, and ensuring that the findings were clear and actionable
📊 What We Found

Negative EPS surprise model evaluation
We prioritised recall because false negatives, missing a potential NES, pose greater risk to regulatory stability than occasional false positives. Catching potential risk early was the higher priority.
Our best model, a tuned XGBoost classifier, achieved recall: 0.75, precision: 0.43
This significantly outperformed the naive and random baselines (recall ~0.50, precision ~0.30)
Including linguistic features did not significantly improve recall, but slightly increased precision, suggesting they might refine predictions but not identify new NES events
SHAP analysis showed that 8 of the top 10 most important features were financial (e.g. Return on Equity, Net Income Growth). However, longer average word and sentence lengths were weakly linked with lower NES risk—possibly indicating more confident executive communication

SHAP plot of feature importances for best model version
We also faced limitations:
A small dataset (n=52 quarters) limited the model's generalisability
NES events were rare, creating instability in validation results
Communication styles varied between firms, making it hard to isolate consistent linguistic signals
🔄 What I'd Do Next
With more data across more banks, we could:
Boost model stability and robustness
Better understand if linguistic patterns generalise across institutions
Refine NLP features to distinguish between "market-pleasing communication" and signals of genuine risk
Test transfer learning approaches or fine-tuned language models across firm-specific communication patterns
🧠 Lessons Learned
This project taught me how to apply machine learning responsibly on small datasets, communicate uncertainty, and collaborate effectively on high-stakes applied research.